
Technical seo is the optimization of the technical elements of the website for search engines. Technical is the last type of search engine. I start with a definition, Importance, factors for ranking, difference, tools, career, and consultation.
What is Technical SEO?
Technical seo is the optimization of the technical elements with the goal of increasing organic/unpaid rankings and making it easy for search engines to crawl, index, and optimize website architecture. Some of the technical elements are CSS, JavaScript, server-side optimization, and CMS configuration according to the search engine guidelines. It also creates solid foundations for on-page and off-page strategies.
Why is Technical SEO Important?
Technical seo is important because if a search engine crawler comes to your website and the website has a technical problem, the crawler is not able to crawl, and if it is not crawled so it is not indexed, and if it is not indexed so it is not ranked. That’s why you need to do technical seo.
What Comes Under Technical Seo?
Under Technical seo, a lot of factors come in, like crawling, budget optimization, JS minify, etc.
Crawling:
Crawling is the process by which Google’s automated programs, known as crawlers or spiders (most famously, Googlebot), discover new and updated pages on the internet. Since there is no central registry of all web pages, Googlebot must constantly explore the web to find content. This discovery happens in several ways:
- Following Links: Googlebot discovers new pages by following links from pages it already knows about. A link from a category page to a new product page, for instance, is a primary discovery path.
- Sitemaps: Website owners can submit an XML sitemap, which is a list of all the URLs on their site that they want Google to crawl.

Once a URL is discovered, Googlebot decides whether to visit, or “crawl,” it. Using a huge set of computers, Googlebot fetches billions of pages from the web. This process is algorithmic, determining which sites to crawl, how often, and how many pages to fetch from each site. This decision is governed by two key concepts:
- Crawl Rate Limit (or Crawl Health): Googlebot is designed to be a good citizen of the web. It limits its crawl rate to avoid overwhelming a website’s server. If a site responds quickly and without errors, the crawl rate limit may increase. Conversely, if a site is slow or returns server errors (like HTTP 5xx codes), Googlebot slows down its crawling.
- Crawl Demand (or Crawl Schedule): This determines how often Google wants to crawl a page. More popular URLs and pages that are updated frequently have higher crawl demand to ensure the content in Google’s index remains fresh (“staleness”).
1. Robots.txt Optimization
Strategic Blocking:
User-agent: Googlebot
# Block parameter-based URLs
Disallow: /*?*sort=
Disallow: /*?*filter=
Disallow: /*?*page=
Disallow: /*?*utm_
# Block development and staging areas
Disallow: /dev/
Disallow: /staging/
Disallow: /admin/
# Block unnecessary file types
Disallow: /*.pdf$
Disallow: /*.doc$
Disallow: /*.xls$
# Allow important parameters
Allow: /*?*category=
Allow: /*?*product=
Sitemap: https://example.com/sitemap.xml2. Server Response Optimization
304 Not Modified Implementation:
<?php
// Check if content has been modified
$lastModified = filemtime($contentFile);
$eTag = md5_file($contentFile);
header("Last-Modified: " . gmdate("D, d M Y H:i:s", $lastModified) . " GMT");
header("ETag: " . $eTag);
if (isset($_SERVER['HTTP_IF_MODIFIED_SINCE']) || isset($_SERVER['HTTP_IF_NONE_MATCH'])) {
if ($_SERVER['HTTP_IF_MODIFIED_SINCE'] == gmdate("D, d M Y H:i:s", $lastModified) . " GMT" ||
$_SERVER['HTTP_IF_NONE_MATCH'] == $eTag) {
header("HTTP/1.1 304 Not Modified");
exit;
}
}
?>Crawler Behavior Analysis:
# Extract Googlebot requests
grep "Googlebot" access.log | awk '{print $1, $4, $7, $9}' > googlebot_requests.txt
# Analyze crawl frequency
grep "Googlebot" access.log | awk '{print $4}' | cut -d'[' -f2 | cut -d':' -f1 | sort | uniq -cPerformance Metrics:
- Response time analysis
- Server error identification
- Resource loading patterns
- Geographic access patterns
Rendering: JavaScript execution in headless Chrome
In the early days of the web, pages were simple HTML documents. Today, many websites rely heavily on JavaScript to dynamically generate and display content. To understand these pages, Google cannot simply read the initial HTML source code. It must render the page, which means executing the JavaScript in a process similar to how a web browser displays a page for a user.
Google uses a recent version of the Chromium browser for this rendering process. This is a resource-intensive step. After the initial crawl of the HTML, pages that rely on JavaScript are placed into a rendering queue. When resources are available, a headless version of Chromium loads the page, runs the scripts, and generates the final Document Object Model (DOM). Without this step, any content, links, or metadata added to the page via JavaScript would be invisible to Google.
1. Server-Side Rendering (SSR)
// Next.js example
export async function getServerSideProps(context) {
const data = await fetchCriticalData();
return {
props: {
title: data.title,
description: data.description,
content: data.content
}
};
}
Resource Hints: Use <link rel="preconnect"> and <link rel="preload"> for critical assets. For example, preconnect performs DNS+TCP/TLS handshake early, shaving ~10–20ms off the initial connection. DNS-prefetch (only resolves DNS) is less powerful than preconnect. Preloading key CSS or font files ensures they start downloading immediately, improving LCP. These hints help the browser fetch needed resources sooner without altering content.
2. Progressive Enhancement
<!-- Ensure core content is in initial HTML -->
<main>
<h1>{{ title }}</h1>
<p>{{ description }}</p>
<div id="enhanced-content">
{{ staticContent }}
</div>
</main>
<script>
// Enhance with JavaScript
document.addEventListener('DOMContentLoaded', () => {
enhanceContent();
});
</script>
3. Structured Data in JavaScript
// Dynamic JSON-LD injection
function injectStructuredData(data) {
const script = document.createElement('script');
script.type = 'application/ld+json';
script.textContent = JSON.stringify({
"@context": "https://schema.org",
"@type": "Article",
"headline": data.title,
"description": data.description,
"author": {
"@type": "Person",
"name": data.author
}
});
document.head.appendChild(script);
}
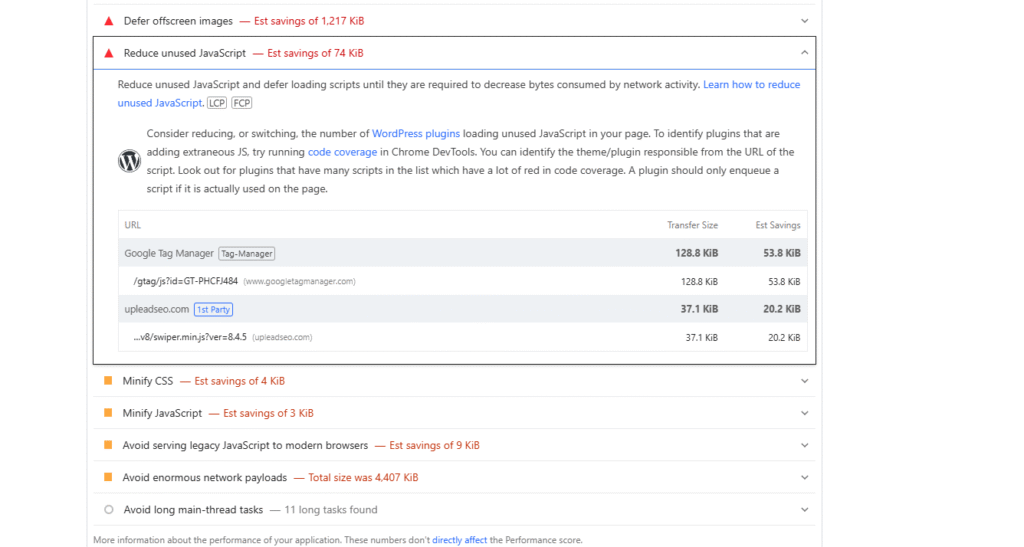
Optimize Script Loading: Place only essential scripts in the <head>, and add defer or async attributes to others to prevent blocking parsing. Deferred scripts execute after parsing, while async scripts load in parallel. Against overusing async: too many parallel scripts can create CPU bottlenecks and actually slow down rendering. He suggests reviewing Chrome DevTools’ initiator chain to detect long JS call sequences and then deferring or splitting heavy scripts appropriately.
Critical Rendering Path: Eliminate render-blocking assets above the fold. That, even with a reasonable DOM size, misordered resources can slow the initial render. Thus, optimizing load order (CSS first, then deferred JS) and using smaller files or compression helps pages become interactive faster. In large sites (news, e-commerce), even a 100–200ms gain per page adds up to big SEO benefits over time.
Common JavaScript SEO Issues and Solutions
Problem 1: Soft 404 Errors
// Solution: Proper status code handling
function handleNotFound() {
document.title = "Page Not Found";
document.querySelector('meta[name="robots"]').setAttribute('content', 'noindex');
// Server should return 404 status
}
Problem 2: Client-Side Routing
// Solution: Use History API
function navigateToPage(url) {
history.pushState({}, '', url);
updatePageContent(url);
updateMetaTags(url);
}Indexing:
After a page is crawled and rendered, Google analyzes its content to understand what it is about. This is the indexing stage. During indexing, Google processes textual content, key HTML tags (like
<title> elements and alt attributes for images, videos, and structured data.
A critical part of indexing is canonicalization. The web is filled with duplicate content—the same page accessible via multiple URLs (e.g., with and without www, HTTP and HTTPS, or with tracking parameters). Google identifies these similar pages and groups them into a cluster. From this cluster, it selects one URL as the canonical version, which is the one that will be shown in search results. The other URLs are considered alternates.
Optimize for Indexing
Canonical URL Implementation:
<!-- For filtered pages that should be indexed -->
<link rel="canonical" href="https://example.com/products/shoes/running/">
<!-- For filtered combinations -->
<link rel="canonical" href="https://example.com/products/shoes/running/?color=blue&size=10">Proper URL Structure:
✅ Good: /products/shoes/running/?color=blue&size=10
✅ Good: /products/shoes/running/blue/size-10/
❌ Bad: /products/shoes/running/?color=blue&color=red&size=10
❌ Bad: /products/shoes/running/?size=10&color=blue&sort=priceCurrent Core Web Vitals Metrics
1. Largest Contentful Paint (LCP) < 2.5 seconds
Optimization Strategies:
<!-- Optimize LCP element -->
<img src="hero-image.jpg"
alt="Hero image"
loading="eager"
fetchpriority="high"
width="800"
height="600">
<!-- Preload critical resources -->
<link rel="preload" href="hero-image.jpg" as="image">
Server-Side Optimizations:
# Nginx configuration
location ~* \.(jpg|jpeg|png|gif|ico|svg)$ {
expires 1y;
add_header Cache-Control "public, no-transform";
add_header Vary "Accept-Encoding";
}
2. Interaction to Next Paint (INP) < 200ms
INP Optimization Approach:
- Minimize JavaScript execution time
- Implement efficient event handlers
- Use web workers for heavy computations
- Optimize third-party script loading
Implementation:
// Optimize event handlers
function optimizeEventHandlers() {
let timeoutId;
document.addEventListener('scroll', () => {
clearTimeout(timeoutId);
timeoutId = setTimeout(() => {
// Debounced scroll handler
handleScrollEvent();
}, 16); // ~60fps
});
}
// Use web workers for heavy tasks
const worker = new Worker('heavy-computation.js');
worker.postMessage(data);
worker.onmessage = (e) => {
updateUI(e.data);
};
3. Cumulative Layout Shift (CLS) < 0.1
Prevention Strategies:
/* Reserve space for images */
.image-container {
aspect-ratio: 16 / 9;
width: 100%;
}
/* Prevent font loading shifts */
@font-face {
font-family: 'WebFont';
src: url('font.woff2') format('woff2');
font-display: swap;
}Hreflang Tags
Hreflang Tags are the attributes that specify the language of the content. This content belongs to which language, which helps the search engine to understand fast and easily, which is our goal. it is also most beneficial for Internationalized or multilingual sites.

URL Structure Decision Matrix
| Structure | Pros | Cons | Best For |
|---|---|---|---|
| ccTLD (example.mx) | Strong geo-targeting | High maintenance | Country-specific businesses |
| Subdomain (mx.example.com) | Moderate geo-targeting | SEO dilution | Multi-regional content |
| Subdirectory (example.com/mx/) | Authority consolidation | Weaker geo-signals | Language targeting |
XML Sitemap Implementation of Hreflang:
<?xml version=”1.0″ encoding=”UTF-8″?> <urlset xmlns=”http://www.sitemaps.org/schemas/sitemap/0.9″ xmlns:xhtml=”http://www.w3.org/1999/xhtml”> <url> <loc>https://example.com/en-us/page/</loc> <xhtml:link rel=”alternate” hreflang=”en-us” href=”https://example.com/en-us/page/”/> <xhtml:link rel=”alternate” hreflang=”en-gb” href=”https://example.com/en-gb/page/”/> <xhtml:link rel=”alternate” hreflang=”es-mx” href=”https://example.com/es-mx/page/”/> <xhtml:link rel=”alternate” hreflang=”x-default” href=”https://example.com/page/”/> </url> </urlset>
Additional Technical SEO Best Practices:
Use Pagination
Pagination is the sequence of numbers assigned to pages on a web page.
Smart Pagination:
// Implement infinite scroll with proper URL updates
class FacetedNavigation {
constructor() {
this.currentFilters = {};
this.currentPage = 1;
this.totalPages = 1;
}
updateFilters(newFilters) {
this.currentFilters = { ...this.currentFilters, ...newFilters };
this.currentPage = 1;
this.updateURL();
this.loadProducts();
}
updateURL() {
const params = new URLSearchParams();
// Add filters in consistent order
Object.keys(this.currentFilters)
.sort()
.forEach(key => {
if (this.currentFilters[key]) {
params.append(key, this.currentFilters[key]);
}
});
if (this.currentPage > 1) {
params.append('page', this.currentPage);
}
const newURL = `${window.location.pathname}?${params.toString()}`;
history.pushState({}, '', newURL);
}
loadProducts() {
fetch(`/api/products?${this.buildQuery()}`)
.then(response => response.json())
.then(data => {
if (data.products.length === 0) {
// Return 404 for empty results
this.handleEmptyResults();
} else {
this.renderProducts(data.products);
}
});
}
handleEmptyResults() {
// Implement proper 404 handling
document.title = "No Products Found";
document.querySelector('meta[name="robots"]').setAttribute('content', 'noindex');
}
}Find & Fix/thin Duplicate Content Issues
Duplicative content should be consolidated (via canonical tags) to focus crawl equity on the best pages. Overall, optimizing crawl budget means maximizing the value of each fetch – e.g., by eliminating duplicate content, fixing errors, and using proper robots directives – so Google’s bots spend time on your highest-value pages.
Use Breadcrumb Navigation
Breadcrumb Navigation helps users and Google bots to identify easily which category this page. where it comes from. Breadcrumb navigation is a secondary navigation aid that helps users understand and traverse the hierarchy of a website or application. It displays the user’s path from the homepage (or top-level section) down to their current page, typically as a horizontal list of links separated by “>” or “/”. It reduces the crawl budget.
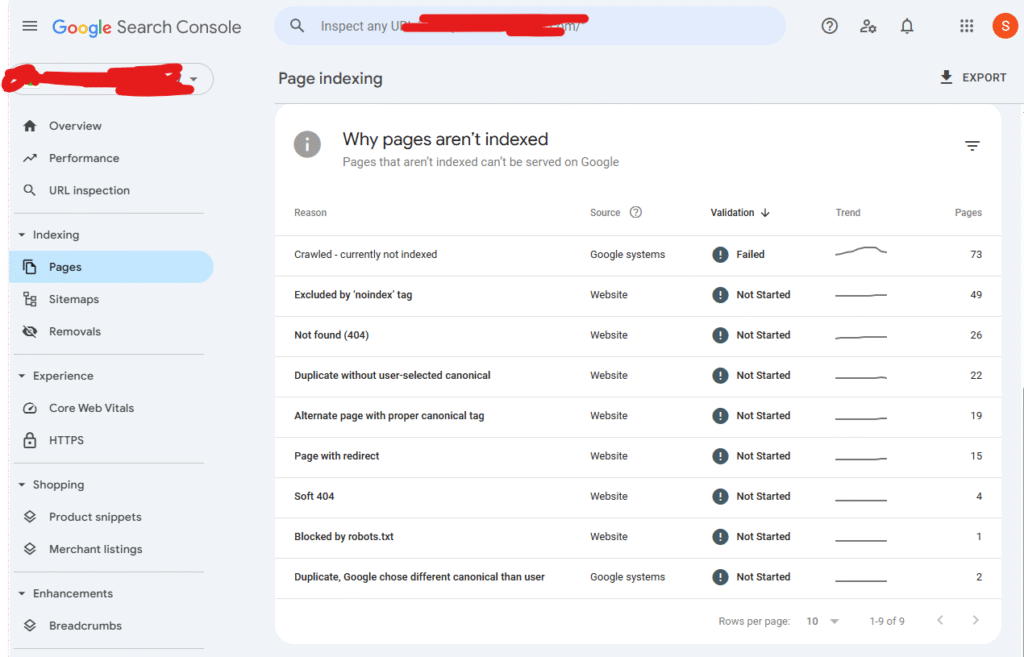
Using Search Console
You can use Google Search Console, which gives you detailed insights about what technical problems on your website. You create a report and fix it, and it will influence the ranking.
Reduce Web Page Size
Reducing the web page size leads to improved speed, which leads to improved ranking.
Top-level site security
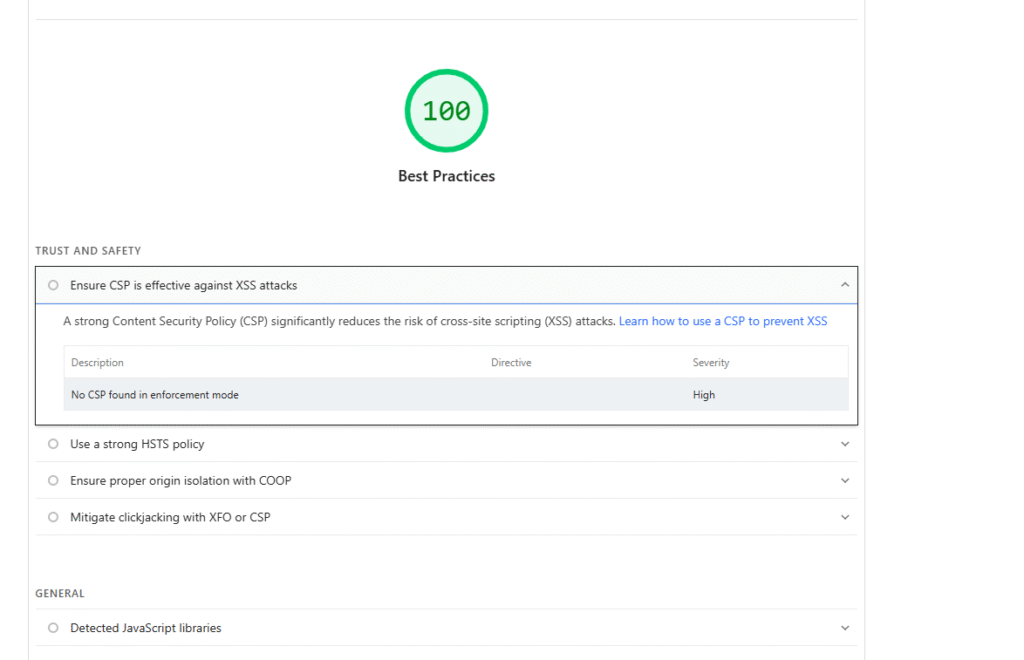
Technical seo includes the top-level security of the website. People use black-hat strategies to rank and breach the website using different attacks like DDOS. The technical elements of top-level site security are HTTPS / TLS (SSL), HTTP Strict Transport Security (HSTS), Content-Security-Policy (CSP), and Proper server segmentation (e.g., DMZ for public-facing sites), etc.
Content management system (CMS):
43 (~472 million sites) to 44% of all websites use WordPress. Every CMS has its own way to optimize, but here are some points that you should remember:
- Plugin/extension Upgradation
- Creating, editing, and formatting content using WYSIWYG editors
- Managing media assets (images, videos, documents) with a media library
- Performance monitoring and caching setup
Log file analysis:
Log file analysis, I think, is the most important aspect in technical seo. Log files are the files that tell us how, when, and which Google crawls a page. On most hosting platforms, including those with cPanel, raw log files can typically be found in the root directory or a dedicated “Logs” or “Metrics” section.
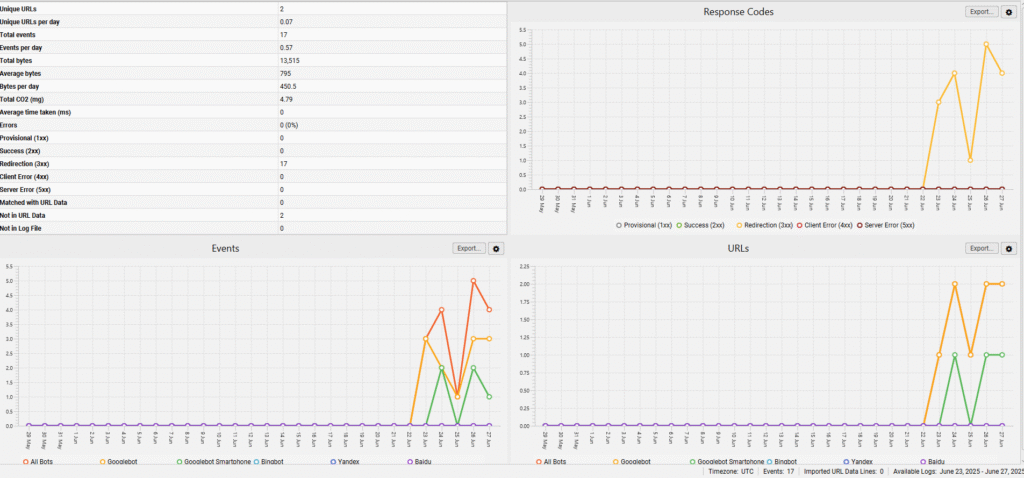
By analyzing these files, you can learn:
- How: Which user-agent (e.g., Googlebot, Bingbot) is crawling your site?
- When: The exact date and time of each crawl.
- What: Which specific pages, images, CSS, and JavaScript files are being crawled?
- Crawl Frequency: How often search engines visit your site.
- Crawl Budget Waste: If search engines are wasting time on unimportant or non-existent (404) pages.
- Server Responses: The HTTP status codes served to crawlers (e.g., 200, 301, 404, 503).
Here is an Example script of log analysis:
# Python script for log analysis
import re
from collections import defaultdict
def analyze_crawler_patterns(log_file):
crawlers = defaultdict(int)
status_codes = defaultdict(int)
with open(log_file, 'r') as f:
for line in f:
# Extract crawler information
if 'bot' in line.lower():
crawler_match = re.search(r'(\w+bot)', line)
if crawler_match:
crawlers[crawler_match.group(1)] += 1
# Extract status codes
status_match = re.search(r'" (\d{3}) ', line)
if status_match:
status_codes[status_match.group(1)] += 1
return crawlers, status_codesPrevent Unnecessary Crawling
Robots.txt Implementation:
User-agent: *
# Block filter combinations
Disallow: /*?*color=
Disallow: /*?*size=
Disallow: /*?*price=
Disallow: /*?*brand=*color=
Disallow: /*?*sort=*filter=
# Allow important single filters
Allow: /*?*category=
Allow: /*?*brand=
URL Fragment Approach:
// Use fragments instead of parameters
function applyFilter(filterType, filterValue) {
const currentHash = window.location.hash;
const newHash = updateHashFilter(currentHash, filterType, filterValue);
window.location.hash = newHash;
// Update content via AJAX
updateProductList(parseFiltersFromHash(newHash));
}
function parseFiltersFromHash(hash) {
const filters = {};
const hashParams = hash.substring(1).split('&');
hashParams.forEach(param => {
const [key, value] = param.split('=');
if (key && value) {
filters[key] = decodeURIComponent(value);
}
});
return filters;
}What’s the differernce between Technical SEO vs on-page vs off-page seo?
Technical SEO: Optimizes a website’s infrastructure for search engine crawling and indexing. It includes site speed, mobile-friendliness, and security (HTTPS). It’s the foundation of the site.
On-Page SEO: Optimizes the content and HTML of individual web pages to rank higher. This involves keyword usage, title tags, meta descriptions, and content quality. It’s what is on the page.
Off-Page SEO: Builds a website’s authority and reputation through actions taken outside the website. This is primarily achieved through acquiring high-quality backlinks from other sites. It’s about your site’s credibility on the web.
| Aspect | Technical SEO | On-Page SEO | Off-Page SEO |
|---|---|---|---|
| Focus | Site crawlability, indexing, speed, security | Content relevance, keywords, meta tags, internal linking | Backlinks, social shares, brand mentions |
| Key Tasks | • XML sitemaps • Robots.txt • Site speed & mobile-friendlines • HTTPS | • Title tags & meta descriptions • Heading structure (H1–H6) • Image alt attributes | link building Guest Post |
| Goal | Ensure search engines can access and interpret site | Make each page clear, relevant, and user-friendly | Build site authority, trust, and visibility via external sites |
How do Tools Help In Technical SEO?
Tools help you to identify, measure, and optimize your technical elements of the website, which gives you the chance to do technical seo. Most famous tools like Edge SEO, Screaming Frog SEO Spider, Lumar (formerly Deepcrawl), Chrome DevTools, PageSpeed Insights, large-scale CSV manipulation applications, and redirect chains.
Thinking of a career in technical SEO?
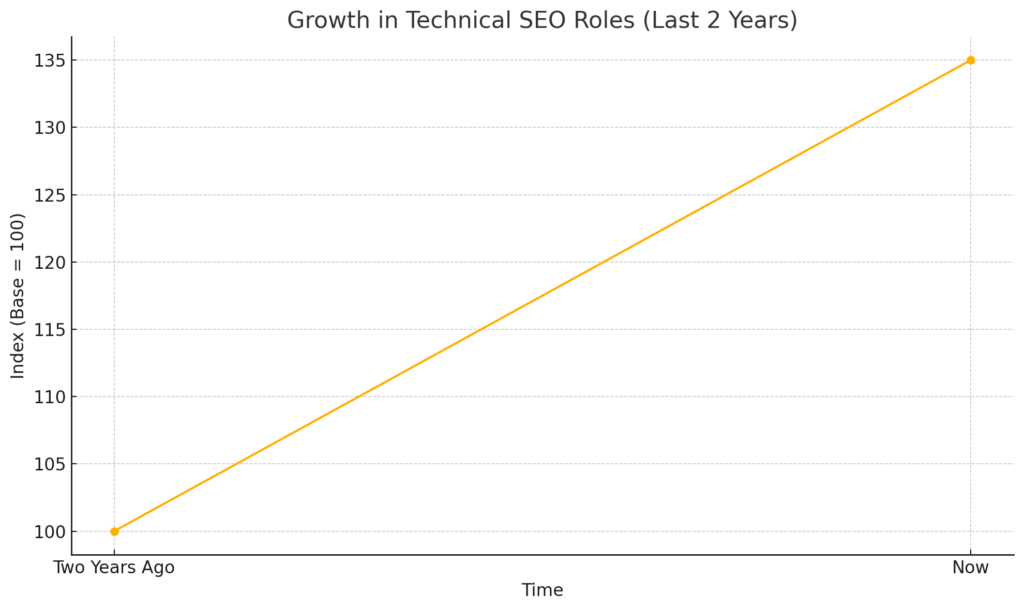
Technical SEO has emerged as a critical specialty within digital marketing, focusing on website architecture, crawling, indexing, and performance optimization. Analysis of leading job portals (e.g., LinkedIn, Indeed) shows a 35% growth in technical SEO roles over the last two years, driven by increased competition and algorithm updates.
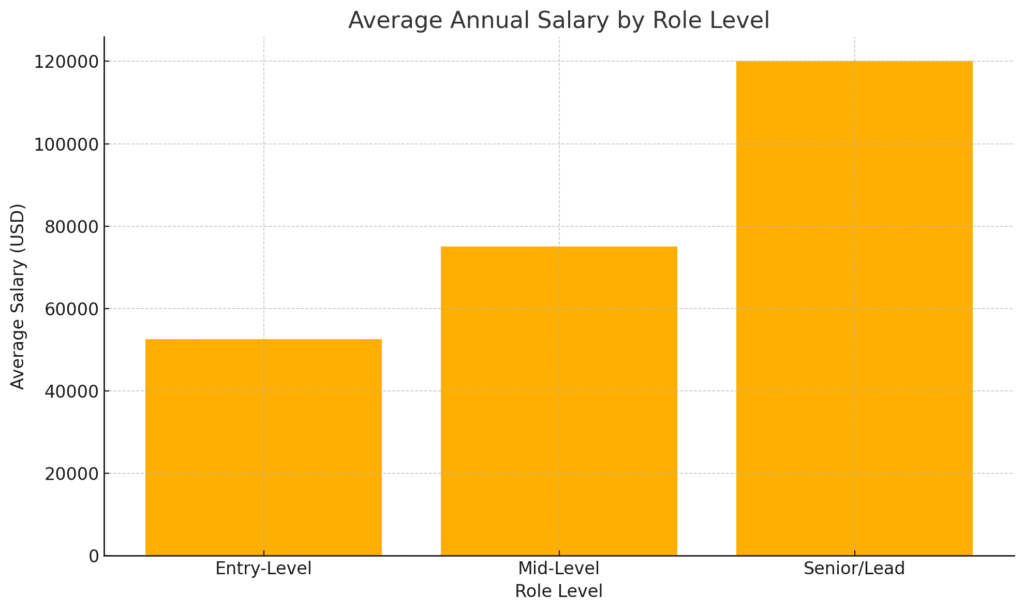
- Entry-Level: $45,000–$60,000 (US figures), varying by region and company size.
- Mid-Level: $60,000–$90,000 with 3–5 years of experience, managing small teams or projects.
- Senior/Lead Roles: $90,000–$150,000+, leading enterprise-level SEO strategy, cross-functional initiatives.
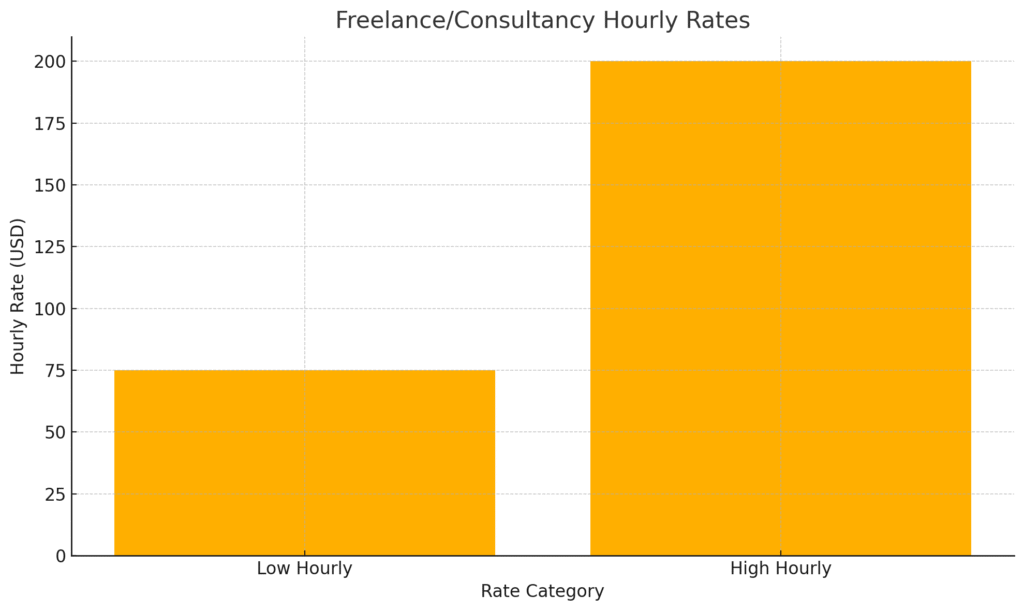
- Freelance/Consultancy: Hourly rates typically $75–$200+, depending on expertise and portfolio.
How do i Learn Technical SEO seo Full?
Upleadseo is the knowledge base or Wikipedia of the seo. Here you will find all guide articles with full details, research, and real knowledge, avoiding the false information that is common in the industry.
Get professional Technical SEO SEO help
Upleadseo provides #1 technical seo services that fulfill your need for a technical seo person. Our strategies are proven, implemented, & results-oriented strategies which make your website in ranking boom.

{kind=link}